A Compiled Backend for Scilla
The Zilliqa blockchain will undergo a critical network upgrade this week which will improve the performance of smart contract (Scilla) execution.

The Zilliqa blockchain will undergo a critical network upgrade this week which will improve the performance of smart contract (Scilla) execution. As described in an earlier blogpost, the Scilla interpreter prior to the upgrade acts like a blackbox. Basically, this means that the interpreter takes (primarily) two inputs:
- the current state of the contract in the form of
state.jsonand - a
message.jsoncontaining information on the transition that needs to be invoked and the arguments that need to be passed to it
Following this, the interpreter returns the updated state reflecting the changes post-contract execution.
The implication of this “blackbox” style of executing a contract is that the interpreter loads and processes the entire state, even though all that it may require (for executing the transition) is a small part of it. Furthermore, as state.json can potentially become extremely large, this “blackbox” model may lead to I/O bottlenecks. The upcoming upgrade will solve this issue and ensure that the interpreter does not read any data that it does not require for a given message.json.
In parallel, we have been working on another enhancement that will further speed up the processing time of a smart contract and will have an impact on the overall throughput and latency of the Zilliqa blockchain. This blogpost is dedicated to present this idea of a compiled backend for Scilla. We start with a brief introduction to compilers and interpreters and then share details on the general architecture and pipeline we plan to implement.
Compilation vs Interpretation
Programming languages are designed for humans to conveniently express their application’s logic to a computer. A programming language is said to be “high level” when it provides abstractions that allow expressing and organising the programmer’s logic and intentions with little effort. On the other hand, a “low level” language provides no abstractions to ease programming and translates into the CPU’s instruction set (almost) directly.
Languages such as Python, Java, OCaml etc., are considered as “high level” languages. “Low level” languages are (mostly) CPU specific. For an x86 CPU, its assembly language can be considered to be the lowest language with which the CPU can be programmed. While high level languages are easier to program with, the CPU only understands its own instruction set. This means that high level languages need to be translated to a low level language (i.e., the CPU’s assembly / machine language) before it can be run.
Consider this simple program written in C:int main()
{
int a = INT_MAX, b = INT_MIN;
printf("a=%d,b=%d,x=%u\n", a, b, a*b);
return 0;
}
and its translated x86 assembly:.text
.section .rodata
.LC0:
.string "a=%d,b=%d,x=%u\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $16, %rsp
movl $2147483647, -8(%rbp)
movl $-2147483648, -4(%rbp)
movl -8(%rbp), %eax
imull -4(%rbp), %eax
movl %eax, %ecx
movl -4(%rbp), %edx
movl -8(%rbp), %eax
movl %eax, %esi
leaq .LC0(%rip), %rdi
movl $0, %eax
call printf@PLT
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu 7.3.0-27ubuntu1~18.04) 7.3.0"
.section .note.GNU-stack,"",@progbits
As you can see, the low-level x86 assembly language is harder to comprehend and consequently program in.
Methods to translate programs written in a high-level language to the CPU’s native instructions (so that it can be executed) can be broadly categorized into (1) interpretation; and (2) compilation. An interpreter directly executes the program from its source code, dynamically translating the parts of it as the program is executing. This means that every execution of the program requires that the interpreter be present, translating instructions based on how the control flows within the program. A compiler, on the other hand, is a software that translates the entire program in one go and produces a translated version of it. This translated program can now be run without further requiring any translation.
If you want to know more about the difference between interpreters and compilers, you can refer to this easy-to-understand introductory video: Interpreters and Compilers (Bits and Bytes, Episode 6).
Compiled Execution for Scilla
Today, smart contracts written in Scilla are interpreted. The Scilla distribution provides the interpreter scilla-runner which takes the Scilla source as its input, along with the current state (of the contract) and the message triggering the transition. scilla-runner interprets (executes) the contract to provide a transitioned state and possibly an outgoing message.
An interpreted execution was chosen for Scilla because (1) interpreters are fairly simple to implement, compared to a full compiler and (2) interpreters being a simpler and smaller codebase can be verified relatively easily (there is an ongoing effort by Zilliqa in formally verifying the interpreter). These two reasons also indicate that it is easier to establish trust on Scilla execution.
While interpreters have advantages, typically they’re slower than executing compiled code. With performance (and lower latency) as a goal, we have started work on building a compiled execution framework for Scilla. In addition to improved efficiency from using a compiled execution model, the project also has the following two benefits:
- The interpreter is a separate executable written in OCaml. Consequently, the blockchain (whose core is written in C++), when it must execute a smart contract, spawns a new process of the interpreter. On the other hand, the compiled backend is a C++ based execution framework, allowing the blockchain to execute a smart contract via shared library calls
- Spawning a separate process for the interpreter also has the drawback that providing the current contract state as input to it requires passing the information through a file (or via inter-process communication). With our proposed compiled backend (which, as mentioned before, will be a C++ shared library), this communication of input to the Scilla contract can be done in-memory
Scilla Virtual Machine (SVM)
Shown below are the various components and their interactions for the proposed Scilla Virtual Machine. This compiled Scilla execution model is based on the LLVM compiler infrastructure.
The Scilla virtual machine has components written in OCaml and C++ and interacts with the blockchain smart-contract module (BC) via C++ shared library calls. The smart-contract module in the main blockchain code is the part of the blockchain that is responsible for executing Scilla contracts upon receiving a message for transition execution.
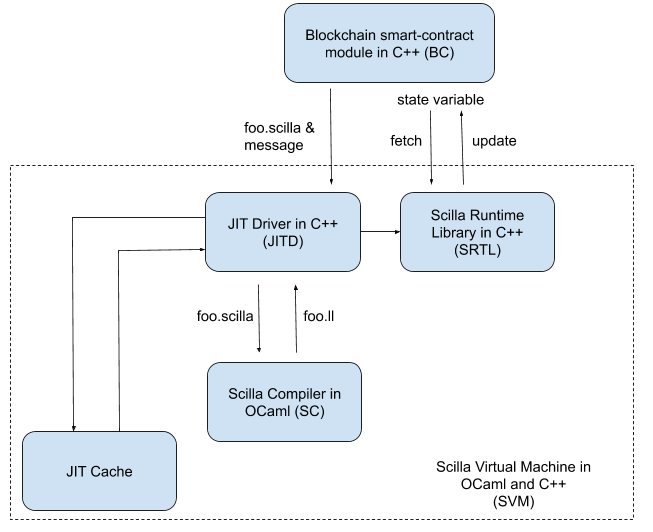
We now proceed to explain the various components in SVM.
Scilla Compiler (SC)
The Scilla compiler is written in OCaml and shares the language frontend (parser) with that of the Scilla interpreter. SC will take a Scilla contract and its dependent libraries as inputs and emits an LLVM-IR module for the whole program.
- The compiler will gradually lower the Scilla AST into LLVM-IR via AST/IR transformation passes such as Monomorphize (elimination of parametric polymorphism) and closure conversion
- An important goal of the Scilla compiler is to preserve type information into the generated LLVM-IR. This helps in establishing trust on the compiler by type checking the generated LLVM-IR
- Though our immediate goal is to build a proof-of-concept compiler, we plan to implement optimization passes and a full garbage collection mechanism later on
Scilla Run-Time Library (SRTL)
The library written in C++ is responsible for performing many common Scilla operations that need not be part of the generated code, but can instead be prewritten utility functions. As a simple example, addition of 256b numbers in Scilla can be translated into a library call to a function in SRTL that efficiently performs this arithmetic. SRTL is also responsible for handling communication between a Scilla transition in execution and the blockchain for fetching and updating state variables.
It is also the responsibility of SRTL to encode (serialize) and decode (deserialize) Scilla values (from the in-memory format) before communicating this with the blockchain (the blockchain itself is agnostic to the contents of state variables — except for the special _balance field). We do not go into the details of this (de)serialization in this article.
One of the goals of this project is to provide a Scilla execution framework that is independent of the blockchain (i.e., it should be possible to make this work on a blockchain other than the Zilliqa platform). With this in mind, we design SRTL to be a shared library that can register callbacks from the blockchain. These registered callbacks are useful for SRTL to call external functions in the blockchain (with the primary example for this being fetching and updating state variables).
JIT Driver (JITD)
The JIT driver (written in C++) is the glue that holds the different components of SVM together. JITD is the face of SVM and is invoked by the blockchain when a contract needs to be executed.
Upon a request for contract execution from the blockchain, JITD invokes the compiler (SC) to generate LLVM-IR for the contract. This LLVM-IR is then JIT (just-in-time) compiled into native (machine) executable code using LLVM’s JIT compilation infrastructure. The machine code is then executed by JITD, providing inputs such as the triggering message, blockchain parameters etc., (the same inputs that are currently provided to the Scilla interpreter, except for the current state — which is fetched / updated as required by SRTL). These inputs are provided to JITD by the blockchain.
JITD also maintains a cache of compiled contracts indexed by the contract’s address. So, when a contract is first deployed, it is compiled and has a copy stored in the cache. From there on, further requests for execution of this contract will not involve compilation of the contract since the compiled machine code is available in the cache. The cache is maintained in a pre-determined directory and the blockchain is not involved in managing the cache (except possibly for a one-time specification of the directory to be used for storing cached contracts).
An Example
Consider a simple contract foo.scilla which has a single transition to update its only Map field.contract Mapper
()
field nmap : Map Int32 String = Emp Int32 String
transition set(k : Int32, v : String)
one = Int32 1;
k1 = builtin add k one;
nmap[k1] := v
end
When compiled with SC, this will result in the following LLVM-IR (shown here as C code for simplicity).void set(int32_t k, const char *v)
{
int32_t k1 = k + 1;
_scilla_builtin_set_map("nmap", k1, v);
}
Note that the compiled code has only functions (for transitions), no state variables.
The LLVM-IR will be JIT compiled (into machine code) by JITD and appropriate function (Scilla transition) executed by passing in the parameters (given to JITD by BC). This execution can involve calls to SRTL, in this case, the call to _scilla_builtin_set_map. The definition for _scilla_builtin_set_map (and other SRTL functions) is written in C++ (for interaction with BC), compiled and linked to JITD. _scilla_builtin_set_map will call BC to update the state variable (nmap), control returns back to the dynamically executed code, the function completes and we’re done.
If foo.scilla was previously seen by JITD, then the compiled code is available in its cache. JITD will avoid recompiling it and will directly execute the function (transition).
Conclusion
With low-latency and optimized execution as a goal, we have outlined an LLVM based compiled backend for Scilla. We are currently working on the Scilla Compiler (SC) and intend to implement the remaining components subsequently. While the architecture of the Scilla Virtual Machine has been finished, we are yet to finalize on many implementation-level details of the entire framework. We will keep you updated on these in future blog articles. We also plan to open-source the implementation.
For further information, connect with us on one of our social channels: