The Zilliqa Design Story Piece by Piece: Part 2 (Consensus Protocol)
Note: ➤ We’re on Slack! Join our community, ask us questions, and get updated on the latest (and hopefully the greatest!)

With our previous article, we started a series to present Zilliqa’s design and protocol details. In the previous article, we discussed the idea of sharding — the core idea that makes Zilliqa scale, i.e., ensures that Zilliqa’s throughput increases (roughly) linearly with the increase in the network size.
In this article, we present the second most crucial component of Zilliqa — its underlying consensus mechanism. Note that while reading the previous article first will certainly be useful, the current one does not require much background baggage either and should be an independent read.
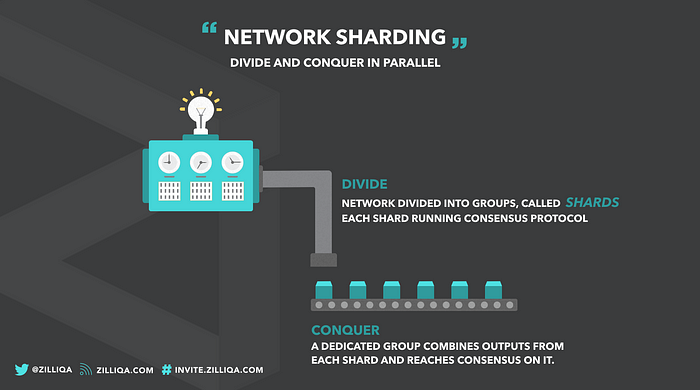
A quick recap of Part 1 on network sharding. In our previous article, we presented the idea of network sharding. Through network sharding, Zilliqa divides the mining network into smaller groups each referred to as a shard. Each shard is capable of processing transactions in parallel and hence yield high throughput. For security reasons, a shard must be sufficiently large, say with more than 600 nodes. Zilliqa performs network sharding using PoW.
Importance of consensus protocol for high throughput
Network sharding on its own cannot guarantee high transaction throughput. This is because the throughput is also determined by how fast each shard can agree on the next set of transactions and propose the next block.
Agreement requires an efficient consensus protocol. The ideal consensus protocol for Zilliqa would be the one that could leverage the small shard size (around 600 nodes) and make each shard reach consensus quickly.
How about using Bitcoin/Ethereum’s consensus protocol?
An alert reader may notice that the shard size mentioned above is much smaller than a regular blockchain P2P network as in say Bitcoin or Ethereum, where the network is composed of tens of thousands of nodes. Then, why cannot Zilliqa use the same consensus protocol (as in Bitcoin/Ethereum) and run it within each shard? Moreover, since the shard size is much smaller than a regular network, the consensus among the shard members could also be reached much faster.
However intuitive this may sound, but, just because the shard size is small, it does not directly yield a fast consensus protocol.
To see this, let us look into the consensus protocol currently in use in Bitcoin and Ethereum. Both these blockchain platforms employ what is often referred to as the Nakamoto consensus (named after its inventor Satoshi Nakamoto who first used it in Bitcoin).
Nakamoto consensus is a very simple and elegant probabilistic consensus mechanism. It works in the following manner: At roughly regular time intervals, the network elects a leader and the leader proposes a block that he thinks should be the next block. He then broadcasts the block to the network and nodes accept or reject it. The leader is incentivized to propose valid blocks that respect some system constraints such as no double spend.
The key to Nakamoto consensus is the way the leader is elected. At roughly regular intervals, each node in the network does a PoW. The node that does it the fastest gets to become the leader. Clearly, PoW must be sufficiently hard so that there is only one leader (with high probability).
PoW being computationally intensive requires time and can slow down the consensus protocol. Moreover, it does not depend on the number of nodes in the network rather on the collective computational capacity of the network. Hence, if employed in Zilliqa, PoW as a consensus mechanism cannot directly leverage the small shard size. This is why Zilliqa needs a different consensus protocol.
Practical Byzantine Fault Tolerance (PBFT) to the rescue
Zilliqa employs practical byzantine fault tolerance protocol aka PBFT for consensus within each shard. The protocol was proposed by Castro and Liskov in 1999. It runs under the assumption that before the start of the protocol a fraction say up to 1/3 of the nodes in each shard can be malicious.
There are several reasons why we chose PBFT as our consensus protocol. The main one being that its efficiency depends on the size of the network and hence can potentially exploit the small size of the shards. Other benefits of PBFT are discussed later in the article.
In PBFT, all the nodes within a consensus group (a shard in our case) are ordered in a sequence, and it has one primary node (aka a leader) and the others are referred to as backup nodes. Every round of PBFT has three phases as discussed below:
- Pre-prepare phase: In this phase, the leader announces the next piece of record that the group should agree on. This is done by sending a “pre-prepare” message.
- Prepare phase: Upon receiving the pre-prepare message, every node validates the correctness and validity of the record and multicasts a “prepare” message to all the other nodes.
- Commit phase: Upon receiving the prepare messages from a super-majority, each node multicasts a commit message to the group. Finally, each node waits for commit messages from a supermajority to ensure that a sufficient number of nodes have agreed on the record proposed by the leader.
In fact, at the end of the three phases, all honest nodes either accept the record or reject it.
PBFT relies upon a correct leader to begin each phase and proceed when a sufficient majority exists. In case the leader is malicious, it can stall the entire consensus protocol. To address this challenge, PBFT offers a view change protocol to replace the malicious leader with another one. In fact, if the nodes do not see any progress for a bounded time, they can independently announce the desire to change the leader. If a super-majority of nodes decides that the leader is faulty, then the next leader in a well-known schedule (such as round-robin) takes over.
Other Benefits of PBFT
Apart from the fact that PBFT can leverage the small shard size, it has several other benefits over Nakamoto-style consensus protocol.

- Transaction finality: PBFT gives finality to the consensus decision. This means that if PBFT is used to reach consensus on the next block, then the proposed block is final and the agreement is exact. As a result, no confirmations are needed. This is in contrast with Nakamoto consensus (as employed in Bitcoin), where the agreement is only probabilistic. As a result, 6 confirmations roughly equivalent to 1 hour is needed to have some cushion against double spend attacks.
- Low energy footprint: Since PBFT is not computationally intensive, it reduces the energy footprint for miners. In fact, Zilliqa uses PoW only to prevent sybil attacks and establish node identities, but not for consensus. This means that once identities have been established, several rounds of PBFT protocol can be run to agree on multiple blocks in a row. As a result, PoW can be done only say after every 100 blocks. This is in contrast with Nakamoto consensus, where a PoW is required per block.
- Low reward variance: PBFT consensus protocol requires collective decision through voting on records by signing messages. This is in contrast with Nakamoto consensus, where, only the leader proposes the next block. Hence with the use of PBFT, the incentive layer can be designed to incentivize every participating node. This further lowers reward variance for miners.
Challenge with PBFT
PBFT is clearly a promising solution to reach consensus in Zilliqa. However, it has a major drawback: it is efficient only when the size of the consensus group is small, i.e., less than 50. But, as discussed in our previous article, for security reasons, the shard size in Zilliqa has to be at least 600.
The main reason why PBFT is inefficient for a large network is its underlying communication overhead. Each node in the consensus group has to talk to every other node and hence this leads to a quadratic communication cost.
In our next post, we will explain how Zilliqa solves this challenge with PBFT. Stay tuned!
Here’s how you can follow our progress — we would love to have you join our community of technology, financial services, and crypto enthusiasts!
➤ Follow us on Twitter,
➤ Subscribe to our Newsletter,
➤ Subscribe to our Blog,
➤ Ask us questions on Slack.